A Python Beginner Guide for My Friend
1. 基础知识
1.1 编程语言
编程语言是你编写程序的方式, 编程语言本身没有什么特别的魔法, 只是一种媒介, 让你可以描述你希望程序如何进行工作. 编程语言有一套固定的编写规则, 在我们写完我们的代码 (Python) 以后, 我们用对应的工具执行我们的代码, 我们的电脑会明白我们需要他做些什么, 执行我们的编写的逻辑, 输出我们要的结果. 你可以理解编程语言是专门设计来和机器/系统沟通的语言.
你可以想象成下面图片中的样子, 我们要写 Python, 我们就需要将 Python 安装到我们的电脑中.
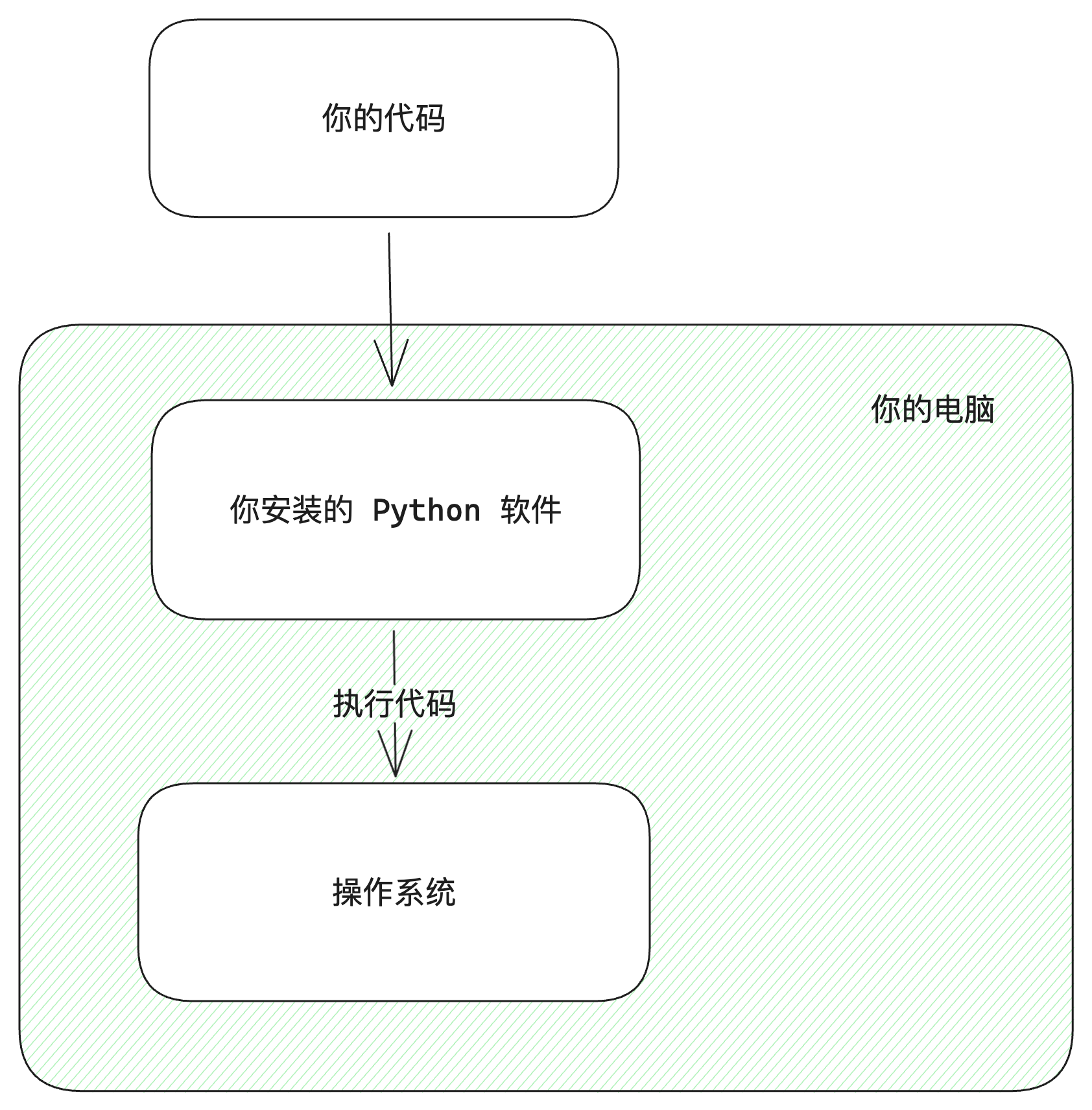
至于在你编写 Python 的时候, 为什么要这样写, 为什么要写这些符号, 你不用太在意这样的疑问. 因为 Python 要求你这样写, 我们就按它要求的方式编写, Python 程序也就能理解我们在写什么, 理解了我们写什么它就能按我们要求的运行. 这背后更深的设计原因暂时先忘记, 先动手再深入.
1.2 操作系统
操作系统本质上就是个软件, 操作系统负责和硬件交互, 我们的电脑可以选择安装不同的操作系统, 但是本质上都是软件. 我们的 Python 代码在编写完后可以在不同的系统上运行, 这是因为不同的系统上安装的 Python 是不一样的, Python 官方自己会适配不同的操作系统. mac 上安装的是 Python mac 版, windows 上安装的是 Python windows 版, 所以绝大部分场景我们不在乎我们的脚本在什么系统上执行.
当我们希望写 Python 代码让我们的操作系统做些什么, 我们只需要按照 Python 要求我们的方式写对应的代码, 我们电脑上安装的 Python 会跟我们电脑的操作系统交互, 操作系统就会去做对应的事情. 例如, 我们希望读硬盘上的一份文件, 操作系统就会去操作硬盘, 加载这份文件的内容.
1.3 命令行
命令行 (windows 上叫做 Command Prompt / 命令提示符) 本质上也就是个软件而已, 只是命令行是一种相对更专业的工具, 专门用于执行命令. 技术人员使用命令行很多时候只是因为以下几个原因:
- 命令行更适合自动化, 例如, 写个脚本跑一大串命令 (页面不好自动点一堆按钮)
- 缺少页面给技术人员点, 没得选, 只能跑命令
- 喜欢命令行 (个人偏好)
2. 准备环境
2.1 安装 Python
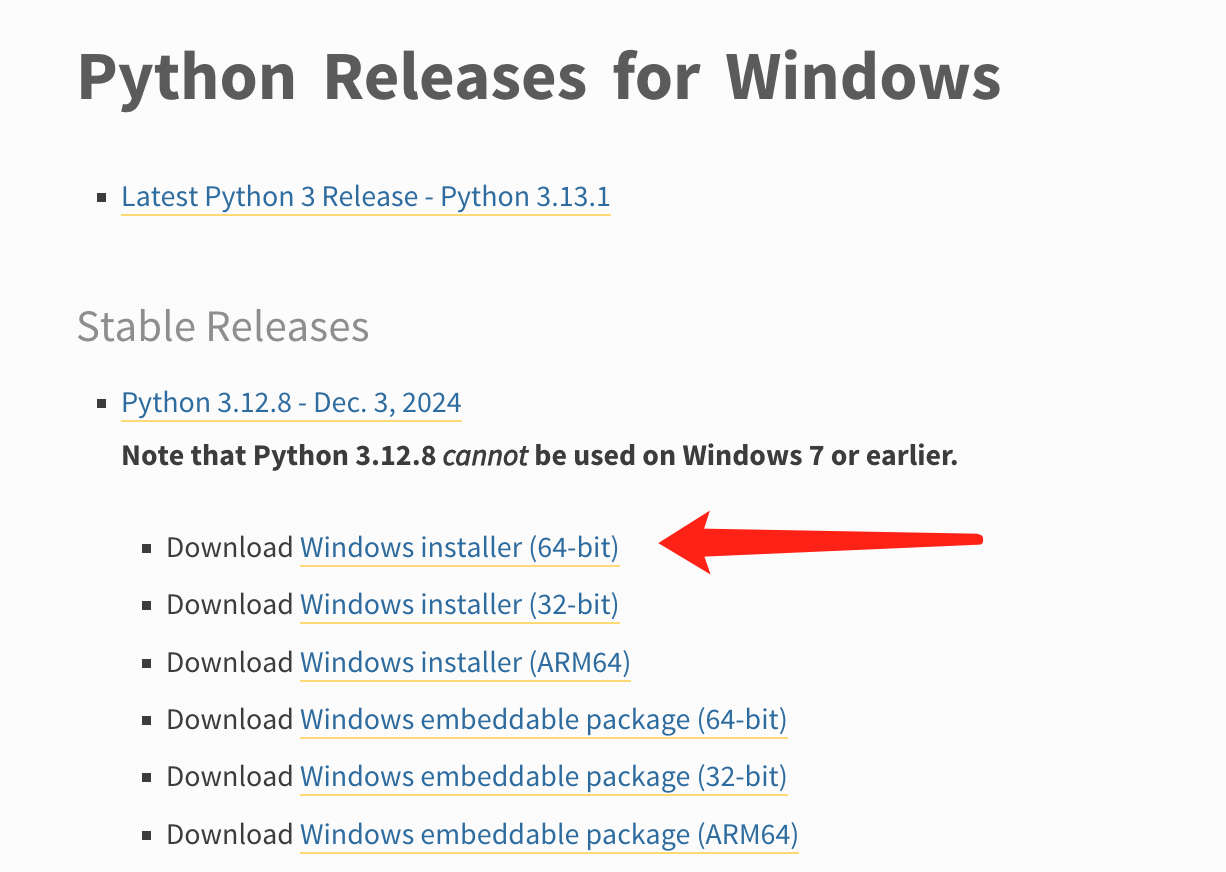
一般来说我们不讲究 Python 的版本, 只要不是太旧就可以, 我们挑个新的版本玩也可以, 例如, 目前最新的稳定版本是 3.12.8.
如下图, 点开官方网站: https://www.python.org/downloads/windows/, 找到 Python 3.12.8, 点击下载 Download Windows installer (64-bit)。
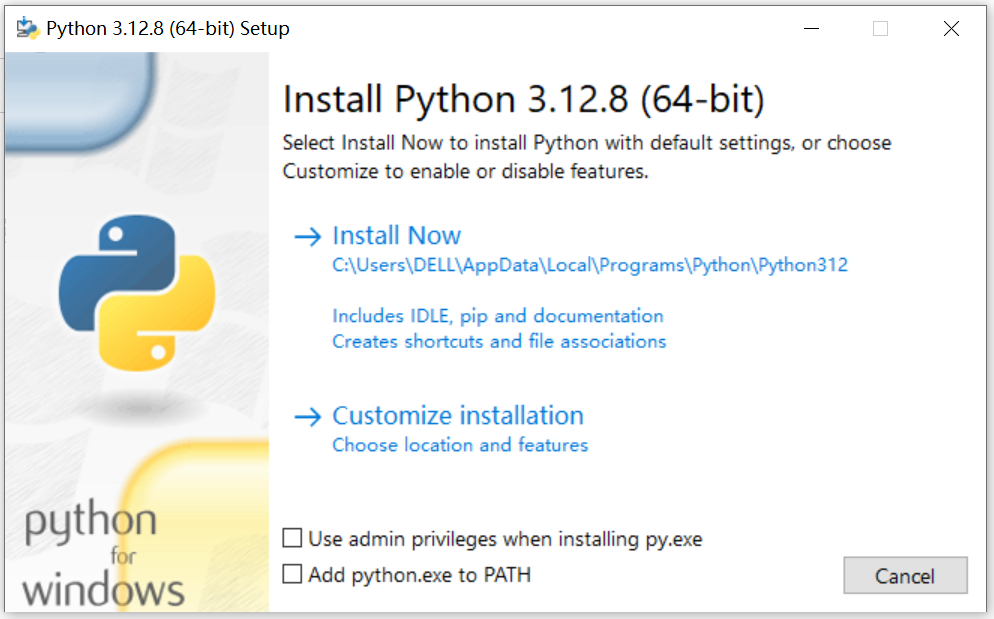
下载后, 打开安装包, 进行安装. 安装的过程中如果有显示 Add python.exe to PATH 这样的内容, 记得将勾选框钩上 (看图片最下方).
安装完成后, 我们可以打开命令行, 验证我们的安装是否有效: 点击 Windows 的图标, 搜索并且打开 Command Prompt (命令行):
输入 Python, 如果你看到显示关于 Python 版本等信息的英文, 你可以看下版本是不是我们现在装的版本 (3.12.8), 如果是, 那么恭喜你, 你成功了.
如果不是, 那么代表安装过程有点问题, 你可以重新安装, 并且确保把 Add python.exe to PATH 勾选框选上.
如果你成功了, 要退出这个 Python 控制台, 输入 exit() 就可以退出, 效果大致如下:
>python
Python 3.12.8 (tags/v3.12.8:2dc476b, Dec 3 2024, 19:30:04) [MSC v.1942 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
2.2 安装编辑器
对于较复杂的编程语言来说, 技术人员通常会选择较多功能的编辑器, 这类统称为 IDE (Integrated Development Environment), 可以理解成这种编辑器软件把大部分功能都塞进去了. 对于 Python 来说, 一般不太需要太 “高级” 的编辑器, 推荐使用 vscode 即可. Python 本身语言较轻, 写起来比较直观, 不需要一大堆工具辅助 (不代表 Python 本身不高级, 只是不会过于不必要的复杂).
编辑器简单的来说就是个文本编辑的软件, 然后我们配套安装些插件, 插件会集成我们上面安装的 Python 从而让编辑器识别我们的代码, 我们就能有一些代码高亮, 代码文档展示, 代码编写错误提醒等基础功能.
打开 vscode 官网: https://code.visualstudio.com/download, 找到 windows 版本, 下载 x64 User Installer 版本:

下载后正常安装安装包, 安装后我们打开这个软件, 在左边导航栏, 选择插件页面 (如下图):
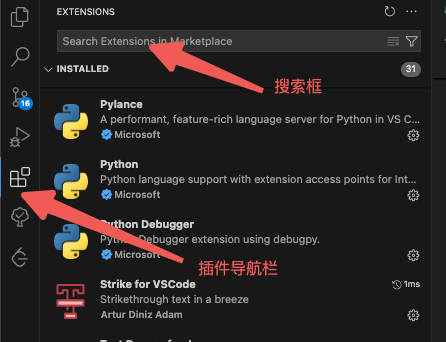
在搜索框中搜索并且安装下图中三个插件, 这三个插件都由微软提供 (我们可以看到 Microsoft 在插件描述的下面):
安装后, 如果 vscode 提醒的话, 重启 vscode, 至此你已经可以开始写 Python 了.
3. 编写 Python
3.1 第一个 Python 脚本
打开 vscode, 选择新建一个文本文件, 按下 ctrl+s 保存到你喜欢的地方, 确保命名带 .py 后缀, 例如: myscript.py. 一般来说一个工程的文件都是放在同一个文件夹层级下.
输入以下内容, 然后 ctrl+s 保存:
msg = "Hello world"
print(msg)
保持在 vscode 页面中, 按下键盘中的 Ctrl+` 键, 这个时候 vscode 会在底部展示出一个控制台.
一般来说你在 vscode 打开一个文件夹,这个控制台所处位置与你的文件夹所在位置是一致的:
例如, 大概长下面这个样子:
PS C:\Users\.....>
如果不在同一个位置, 你可以点击页面最上方 File 下拉框, 选择 Open Folder..., 然后再打开你的文件夹 (你的脚本的位置).
这个时候你可以输入以下命令来运行我们的第一个脚本:
python myscript.py
这个时候控制台应该会运行我们的代码, 同时打印出 "Hello world", 这就算运行成功了.
现在我们来理解第一个 Python 脚本, 脚本本身很简单, 但是大部分复杂的脚本本身也是基于这些基础的东西写出来的, 所以不用觉得没有意义:
脚本的第一行:
msg = "Hello world"
我们可以看出这是个等式, 在大部分编程语言中, 等号就是赋值的意思, 也就是说 = 的左侧被赋予了右边的值 “Hello world”.
在等号的左侧是一个变量, msg 是这个变量的名称, 我们在编写代码的时候会使用多个变量, 给变量赋值, 用来存储我们计算的结果. 这里, 我们就创建了一个变量 msg,
同时让它的值为 “Hello world”.
然后在脚本的第二行中:
print(msg)
我们使用了函数 print(), 我们将我们上面创建的变量 msg 传入到这个函数中, 而这个函数 print() 正如它的英文名称 print 一样, 它负责将我们提供的内容打印出来,
也就是输出到我们的控制台中.
如果你不理解什么是变量, 什么是函数, 不用担心, 下面会尽可能描述清楚. 代码本身不是难点, 而代码要实现的事情才是难点.
3.2 代码注释
代码注释的意思就是, 给代码写说明. 注释是有固定格式的, 也就是以 # 开头后面的内容都是注释的内容.
代码注释是不会被运行的, 也就是说不管你注释内容里写什么, 都不影响程序本身, 只是程序员写给自己看或给别人看的说明.
例如:
a = 1 # a 是 1, 这段灰色的字是解释, 没有实际意义
你会在后续的例子中看到不少注释的使用.
3.2 变量
变量 (Variable) 这个概念源于数学, 在编程中, 变量就是一个有名称的, 可以存储值的抽象概念. 例如,
a = 1
b = 2
c = a + b
上面有三个变量, 分别命名为 a, b, c. 代码执行的时候一般是从上往下, 从右往左执行的, 也就是说, 这个脚本运行的过程如下:
- 创建变量 a, 给 a 赋值 1
- 创建变量 b, 给 b 赋值 2
- 创建变量 c, 给 c 赋值 a + b 也就是 3
基于变量的概念, 我们可以往变量里存数据, 也可以从变量取数据. 你可以理解成, 等号左边的是存数据, 是赋值, 其他情况是从变量读数据.
Python 的变量名一般是: 单词 + 下划线
例如: user_info
核心就是用下划线分隔开单词的缩写, 读起来更清晰, 像 user_info 基本不用想就是个装了各种用户信息的变量.
3.3 数据类型
不同的数据会有不同的数据类型, Python 本身支持的有:
- 整数
- 浮点数 (就是带小数点的)
- 字符串 (一串字符, 所以称为字符串, 例如: “HELLO” 本质上是 “H”, “E”, “L”, “L”, “O”, 5 个字符的集合表达形式), 一般用双引号来表示
- 布尔值, 也就是
True和False - 空值, 代表没有值, 代码中以
None表示
我们编写 Python 代码给变量赋值的时候, Python 会推断变量的数据类型.
msg = "Hello world" # 这是字符串
print(msg)
msg = 1 # 这是整数
print(msg)
msg = 1.1 # 这是浮点数
print(msg)
Python 不要求变量总是只使用一种数据类型, 也就是说你赋值啥, 变量就是啥. 当然, 一般来说不推荐, 因为你会把自己弄懵.
3.4 运算符
我们可以对代码写的值进行运算, 也可以基于变量进行运算, 这些我们统称为运算符. 常见的运算符有 (实际有更多, 但我们先不陷进去):
+: 加法, 或者拼接字符串-: 减法*: 乘法/: 除法%: 求余>: 比较数值, 或者字符串排序, 大于>=: 比较数值, 或者字符串排序, 大于等于<: 比较数值, 或者字符串排序, 小于<=: 比较数值, 或者字符串排序, 小于等于==: 比较值是否相等, 例如, 比较整数, 字符串, 布尔值!=: 比较值是否不相等, 例如, 比较整数, 字符串, 布尔值is: 比较两个变量是否为同一个, 例如, 检查 msg 是否为空:msg is Noneis not: 比较两个变量是否为同一个, 例如, 检查 msg 是否不为空:msg is not Nonein: 检查值是否在数据结构中 (看不懂没关系, 知道是个检查就可以了)not in: 检查值是否不在数据结构中 (看不懂没关系, 知道是个检查就可以了)
基本上也就上面这些运算符, 除去数学的, 基本也没剩几个了. 下面是个对这些运算符使用的例子:
例如, 加减乘除:
a = 1 + 2 # a 是 3
a = 1 - 2 # a 是 -1
a = 1 * 2 # a 是 2
a = 1 / 2 # a 是 0.5
a = 3 % 2 # a 是 1
例如, 比较, 比较的结果实际上是布尔值 (True / False):
a = 1 > 2 # a 是 False (1 是否大于 2)
a = 1 < 2 # a 是 True (1 是否小于 2)
a = 2 >= 1 # a 是 True (2 是否大于等于 1)
a = 2 <= 1 # a 是 False (2 是否小于等于 1)
a = 2 == 1 # a 是 False (2 是否等于 1)
a = 2 != 1 # a 是 True (2 是否不等于 1)
例如, 检查两个变量是否为同一个, 使用 is 和 is not (注意, 同一个不是代表值相等), 一般我们只用 is/ is not 判断变量是否为空:
a = 1
b = a is None # b 是 False, 因为 a 有值, a 不是 none, 值为 1
b = a is not None # b 是 True, 因为 a 有值, a 不是 none, 值为 1
例如, 检查值是否在数据结构中, 使用 in 和 not in (不懂什么是数据结构没关系, 就是拿来装数据的):
my_list = [1, 2, 3] # 我们有个列表, 里面有 1, 2, 3
if 1 in my_list: # 检查数字 1 在不在 my_list 里面
print("my_list 里面有 1")
if 4 not in my_list: # 检查数字 4 在不在 my_list 里面
print("my_list 里面没有 4")
后续你会基于这些判断写条件:
a = 1
if a > 0:
print("a 居然大于 0")
if a is not None:
print("a 不是 None")
3.5 条件判断 / 逻辑分支
当我们开始准备学条件判断, 开始写函数的时候, 我们要开始学习下 Python 的代码格式. Python 代码是以 Tab 来进行行缩进, 用于区分当前代码的位置 (归属于哪个逻辑分支).
我们先简单介绍 if ... else ... 来方便你理解什么时候要加 Tab, (if ... else ... 中文来说就是 如果满足 a 做 b 否则做 c)
1| a = 1
2| if a == 1:
3| print("a 是 1")
4| else:
5| print("a 不是 1")
在上面例子中:
- 第一行我们创建了变量 a
- 第二行我们比较 a 是不是等于 1
- 第三行我们增加了 Tab 缩进, 也就是说
print("a 是 1")是在if a == 1:层级下, 只有当 a 等于 1 时才会执行 - 第四行是
else:说明,else:层级下的代码, 只有当 a 不等于 1 时才会执行 - 第五行我们增加了 Tab 缩进, 说明第五行只有在第四行满足的时候才会执行
如果我们想, 我们可以在通过 Tab 缩进, 在一个逻辑分支下写很多行代码, 例如:
a = 1
if a == 1:
print("a 是 1")
print("a 真的是 1")
print("a 真的真的是 1")
条件判断 / 逻辑分支主要有以下几种:
-
如果 a 做 b (if …)
a = 1 if a >= 1: print("a 大于等于 1") -
如果 a 做 b 否则做 c (if … else …)
a = 1 if a >= 1: print("a 大于等于 1") else: print("a 小于 1") -
如果 a 做 b 但如果 c 做 d 否则做 e (if … elif … else …)
a = 2 if a >= 3: print("a 大于等于 3") elif a >= 2: print("a 大于等于 2") else: print("a 是其他") -
只要 a 一直重复做 b (while …)
例如, 只要 a 小于 4, 下面代码就会打印一次 a 的内容, 同时给 a 加 1, 直到 a 小于 4.
a = 1 while a < 4: print("a 现在是", a) a = a + 1
条件判断还可以嵌套, 只要你需要, 不要太考虑美观问题, 只要合理就可以:
a = 1
if a > 0:
print("a 大于 0")
if a == 1:
print("a 还等于 1 呢")
else:
print("a 小于等于 0")
3.6 函数
函数 (Function) 同样是源于数学的概念。函数由以下几个部分组成:
- 函数的输入 (外部提供给函数的内容), 也常叫入参 (输入参数)
- 函数的名称
- 函数内部的逻辑, 我们通常会写函数, 基于入参做一些运算
- 函数的输出, 函数进行运算完以后, 返回给外部的内容
Python 有大量的内置函数, 也就是 Python 这门语言写好的功能, 如果我们想要使用, 我们直接基于这些函数的名称, 将函数定义的入参传给它们即可.
回顾下上面我们第一个脚本:
msg = "Hello world"
print(msg)
print(..) 就是我们见到的第一个内置函数, 这个函数负责将入参输出到控制台中, 而我们提供的入参正是定义好的变量 msg, 所以函数最终的行为是打印 “Hello world”.
除了内置函数, 我们还可以引入别人写的代码 (的函数), 也可以自己写函数自己用.
函数的写法是: def 函数名(参数名), 例如, 我们写了个函数, 将函数中的第一个参数和第二个参数相加:
def add_num(a, b):
return a + b
我们使用函数是为了做些什么事, 执行一段的代码, 有的时候我们需要拿到函数返回的内容, 我们会使用 return 关键词, return 会将结果返回出去.
写好该函数后, 我们可以用这个函数的名称进行使用, 这里 c 被赋值, 而 c 的值正是来源于 add_num 函数中的 return 值.
a = 1
b = 2
c = add_num(a, b) # c 是 3
但是 return 并不是必要的, 如果你不需要函数返回值, 你不需要在函数里写 return.
3.7 数据结构
数据结构是个专业名词, 英文是 Data Structure, 也就是设计用来装数据的结构, 因为你不是专业程序员, 不用特别专研有哪些数据结构. 不同类型的数据在取/存的时候, 使用不同的数据结构会有不同的效率, 熟练的程序员选择合适的那个数据结构最大化程序的效率. 但是就算效率低有的时候也能完成工作, 不用太在意.
数据结构本身有很多种, 有的设计特别复杂, 但基本上我们平时用得多的也就两种:
- 数组 (本质就是一个紧凑的列表)
- 字典 (一个 key 对应一个 value)
数组就类似于, 你把一个个空的桶放成了一排, 每个桶可以装一个东西, 数组就是这一整排的桶. 当你要往数组放东西的时候, 你可以从头开始或者从尾开始, 一个个检查看桶是不是空的, 如果不是空的就看下一个, 如果是空的, 你就可以把东西放进去. 这种一个个桶看的动作, 编程里叫做 “遍历”, 英文叫做 “iterate”. 如果这一排的桶都满了, 那么你会在这排最后一个桶后面放更多的空桶, 让这个数组变得更长, 这种操作一般称为 “扩容“, 因为数组的容量变大了.
字典就类似于, 在数组的基础上额外增加了份目录. 这份目录中我们给桶标了记号, 例如, 桶-A, 桶-B, 桶-C 等等等等. 通过编号你可以一下子找到桶是哪个, 你不需要一个个看. 在我们要放东西到字典前, 我们先通过固定的规则, 算出这个东西应该放哪个桶, 我们记录下来, 然后我们把这个东西放到对应的桶里. 而这个计算放在哪里的值, 我们统称为 key, 一个 key 会有对应的一个桶, 如果我们下次要找这个 key 的内容是什么, 我们可以快速基于字典的目录定位到桶, 直接拿出来.
基于这样的特征, 你也能尝试理解为什么这个数据结构被叫为字典, 因为字典就只是这样工作的: 单词有排序规则, 目录页记录单词在字典里的页码.
3.8 数组
数组很简单, 本质就是紧凑的一排桶, 这一排桶是有顺序的. 我们使用 [] 创建空数组, 我们也可以像 [ 1, 2, 3, 4 ] 这样创建带有值的数组.
因为数组中这一排桶是有顺序的, 我们可以基于桶的位置进行读取. 数组中的第一个桶的位置是 0 (所有语言都是这样设计的, 不纠结).
buckets = [1, 2, 3, 4]
a = buckets[0] # 读第一个桶, a 现在等于 1
a = buckets[1] # 读第二个桶, a 现在等于 2
a = buckets[2] # 读第三个桶, a 现在等于 3
a = buckets[3] # 读第四个桶, a 现在等于 3
如果我要遍历数组的所有内容怎么办, 有三种方法, 第一种是从 0 数到最后一个桶:
要知道最后一个桶的位置, 首先要知道数组的大小, 我们使用 Python 内置的函数: len():
buckets = [1, 2, 3, 4]
a = len(buckets) # a = 4
因为第一个桶的位置是 0, 最后一个桶就一定是数组的大小 - 1, 所以我们知道最后一个桶就是: len(buckets) - 1.
所以我们可以写以下代码遍历所有的桶:
buckets = [1, 2, 3, 4]
i = 0
while i < len(buckets):
a = buckets[i]
print(a)
i = i + 1
第二种方法是 for ... in, 也就是让 Python 自己帮你遍历数组, 这种是最简单的, 就像写英语一样, 不用在意桶的位置:
buckets = [1, 2, 3, 4]
for a in buckets:
print(a)
3.9 字典
我们基本上绝大部分情况使用字典, 字典的 key 都是字符串或者数字, value 则是随便我们觉得顺手的值:
要创建一个字典, 我们使用 {}:
例如:
names = {}
我们也可以创建一个带有 key-value 的字典, 例如:
goods_count = {
"apple": 100,
"orange": 30
}
我们用 in / not in 检查一个 key 是否在字典里. 同时我们使用 字典名[KEY名称] 来读写字典的值.
例如:
names = {}
# 检查 yongjie 是否在 names 里
if "yongjie" in names:
print("在")
else:
print("不在")
# 把 yongjie 作为 key 放进 names 里, value 随便写点什么, 这里就写 1
names["yongjie"] = 1
if "yongjie" in names:
print("现在在了")
# 读这个 "yongjie" 对应的值是什么
a = names["yongjie"] # a 是 1
print(a)
那字典有什么实际的用途呢? 想象你有一份商品列表, 商品有名称, 种类, 有数量, 我们可以用字典做统计.
假设这个列表长下面这样, 一个表格, 本质上就是一个数组里面装了更多的数组:
[
["红苹果", "苹果", 1],
["青苹果", "苹果", 2],
["黄香蕉", "香蕉", 2],
["水梨子", "梨子", 2],
]
你可以想像成以下这个样子:
| 名称 | 种类 | 个数 |
|---|---|---|
| 红苹果 | 苹果 | 1 |
| 青苹果 | 苹果 | 2 |
| 黄香蕉 | 香蕉 | 2 |
| 水梨子 | 梨子 | 2 |
那么我想计算, 各种类一共卖了多少, 我可以用字典进行分类汇总:
# 假设表格长这样
table = [
["红苹果", "苹果", 1],
["青苹果", "苹果", 2],
["黄香蕉", "香蕉", 2],
["水梨子", "梨子", 2],
]
# 汇总字典
summary = {}
# 遍历数组
for row in table: # 每一行同时也是个数组
name = row[0] # 每一行的第一个, 名称
category = row[1] # 每一行的第二个, 种类
count = row[2] # 每一行的第三个, 个数
# 开始汇总
if category not in summary: # 如果之前没有这个种类, 字典的这个种类的值就是 count
summary[category] = count
else: # 如果之前有这个种类, 字典的这个种类的值就是: 之前的数量加上现在的种类的 count
summary[category] = summary[category] + count
# 你可以把字典打印出来看长什么样
print(summary)
# 长这样
#
# {'苹果': 3, '香蕉': 2, '梨子': 2}
既然数组可以遍历, 字典肯定也是可以遍历的, 但是字典中的桶没有顺序, 所以我们不能直接用数字去指定读哪个桶.
不过我们同样可以用 for ... in 来遍历, 只不过我们遍历的是字典的 key, 然后我们那 key 去读字典的值.
summary = {"苹果": 3, "香蕉": 2, "梨子": 2}
for key in summary:
print("key:", key, "value:", summary[key])
# 输出的结果如下:
# key: 苹果 value: 3
# key: 香蕉 value: 2
# key: 梨子 value: 2